How to avoid duplicates during an import?
There is always a chance that you may have contacts with the same name (e.g., John Smith). For this reason, whenever you run an import in Pipedrive, you will be given the option to recognize and merge duplicates together. You can also choose to bypass this merging step if you prefer to create multiple records.

If you are not sure which one is right for you, it can be helpful to understand how Pipedrive searches for duplicates and how it handles them in this article.
Deals
Given that the nature of sales is that you may have multiple deals with the same name, there is no duplicate identifier for deals in Pipedrive. This means that if you import more than one deal with the same name, those deals will not be considered duplicates and all of them will be imported.
People
Once a Person's name has been recognized in the import, Pipedrive will look for the following information to determine if there is a duplicate record:
Person - Organization
Person - Phone
Person - Email
If Pipedrive finds that ANY of those three fields matches another person within the Pipedrive database or the import file, it will merge them together and add any new data included in the import.
Organizations
Once an organization's name has been recognized in the import, Pipedrive will look for the following information to determine if there is a duplicate record:
Organization - Address
You can have organizations with the same name as long as you always specify the address field. If the address matches any existing organization in your Pipedrive database or import file, it will merge the organizations and add any new information included in the import.
Examples
Merging data
Let’s say you import this list of people and all have the same name. In this example, you would eventually end up with two Jon Snows, because matching criteria was found in three of the same rows.
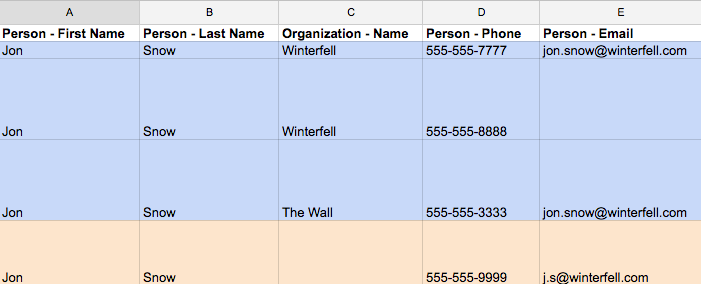
Matching criteria:
1. Jon Snow in row 1 is created.
2. Pipedrive recognizes “Jon Snow” in row 2 and checks for a matching organization, phone and/or email. It then realizes the person - name and organization - name are the same in row 2 as they were in row 1 and therefore does not create 2 Jon Snows. Instead, it maps row 2’s unique phone number onto the same phone number created in row 1.
3. Pipedrive recognizes “Jon Snow” in row 3 and checks for matching organization - name, person - phone and person - email. It then finds that the person - email is the same as in row 1 and therefore does not create an additional Jon Snow. Instead, it adds the new Phone number to row 1’s record, as well as updates row 3's organization - name with “The Wall”.
4. Pipedrive recognizes “Jon Snow” in row 4 but this time finds no matching organization - name, person - phone, or person - email to the existing Jon Snow. It, therefore, creates a second Jon Snow with this unique phone number and email address.
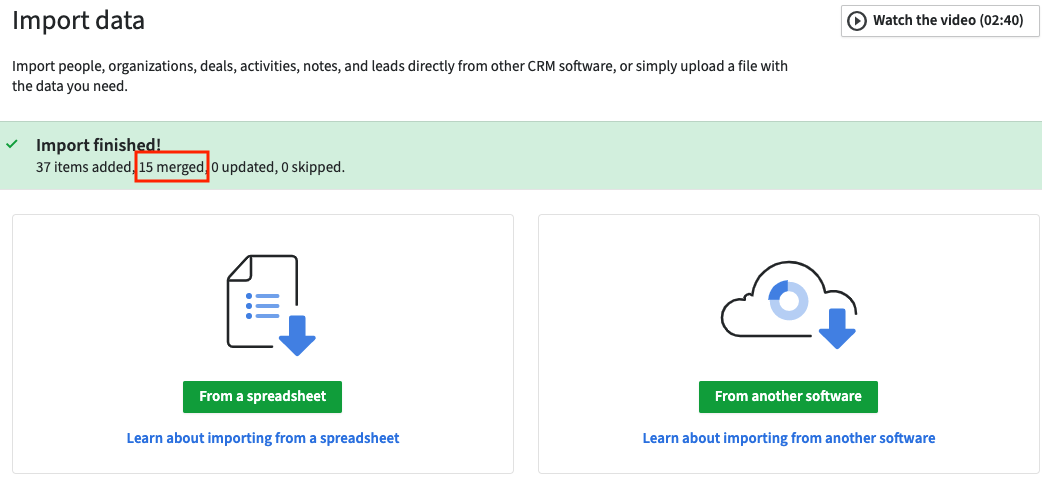

Creating multiple records
As mentioned at the beginning of this article, you are able to select the option to bypass the merging step. The option to create multiple records could be useful in scenarios when you would like each user to have their own copy of those contacts to work with. It is important to keep in mind that each contact created can have only one owner linked to it.

Please note that creating multiple records could create a cluttered database. If you want more than one user linked to a contact, you can create one single item and add the other users as followers. By doing this, the owner and followers will have visibility of this item and will be able to work on it, without the need of creating multiple records.
Was this article helpful?
Yes
No